Published at:
From Self-Hosting to Cloud-Managed: Kinguin’s Journey of Migrating to MongoDB Atlas
In the modern age of technology, businesses need databases that can handle large amounts of data and adapt to changing needs. Kinguin, a leading digital marketplace for video games, found that MongoDB Atlas was the perfect solution for their dynamic environment. Kinguin's self-hosted database cluster provided a stable and easy-to-manage database solution for several years. However, as the business grew, managing the cluster became more challenging, requiring more resources and expertise. In this article, we will explore how Kinguin integrated MongoDB Atlas into their infrastructure and the benefits and challenges we experienced throughout the process.
MongoDB is a highly-scalable, open-source, noSQL database which provides a flexible data-model ideal for dynamic environments like Kinguin Infrastructure. Overall, MongoDB offers a modern and flexible database solution that is designed to handle the challenges of modern applications.
At Kinguin we have been using self-hosted MongoDB for a few years and it was reliable to use. But as our company got bigger, it became harder to keep the database working well and to manage all the things that used it. Some of the problems we encountered, included:
- Index management in self-hosted MongoDB Clusters - as it affects the performance, storage requirements, and overall efficiency of the database there are some common index management problems that can arise in self-hosted MongoDB clusters, like:
- Index creation and deletion
- Incorrect index usage
- Performance issues
- Resource requirements and management of self-hosted MongoDB
- Configuration changes
We searched for a managed solution that would guarantee system safety, stability, and minimal maintenance effort, with additional support. We found MongoDB Atlas, a managed solution with professional support to help solve any issues. To prepare for a highly-scalable, geo-redundant, multi-region environment in 2023, we decided to migrate our DB clusters to MongoDB Atlas after researching several scenarios.
MongoDB Atlas is a cloud-based database service provided by MongoDB. Benefits include easy scalability, robust security features, high availability with automated backups and failover, comprehensive monitoring and alerting tools, fully managed service, global coverage across major cloud providers, and flexible pricing options based on usage. It runs in the same cloud and region as our services, with real-time performance metrics and automated backups.
Migrating to MongoDB Atlas was a big decision for us, but we knew it could unlock new opportunities and improve our operations. After research, we were confident it would pay off. The main benefit was access to a managed cloud database service, freeing us from server maintenance and allowing us to focus on our business.
Migration Overview
As a new service that required adoption we needed to make an initial research and carefully plan our migration strategy. This was needed in order to avoid issues such as long delays during data transfer, connection problems to new environments or any other technical issues that may arise during the migration phase.
Phase 1: Planning and Preparation
- Define the scope of the migration and identify the databases that need to be migrated:
We had more than 50 services that were using mongo all the time and switching them off at the same time would have been quite problematic for us. That’s why we needed to research ways for doing live migration without or with minimal downtime. There are several ways available for doing the mongo cluster-to-cluster migration (Live migration using pull or push data migration techniques, mongodump or mongoexport and mongomirror). We found mongomirror to be the most flexible tool for our use case. It integrates with our pipeline, can be started on demand, and keeps the oplog sync process running for enough time to ensure a seamless migration process. That’s why we decided to use mongomirror as a tool for migrating service by service to Atlas. - Keeping the data as close to the services as possible. MongoDB provides multicloud support that also runs on VPC peering. This allowed seamless communication between our microservices and mongo clusters with less than 10ms latency.
- VPC peering along with the speed benefits, provided us with the security needed for running our clusters on private networks with fully governed access.
- After transferring our non-production data and fully testing our migration patterns we defined a timeline and schedule for the migration process.
Reference Architecture of our network
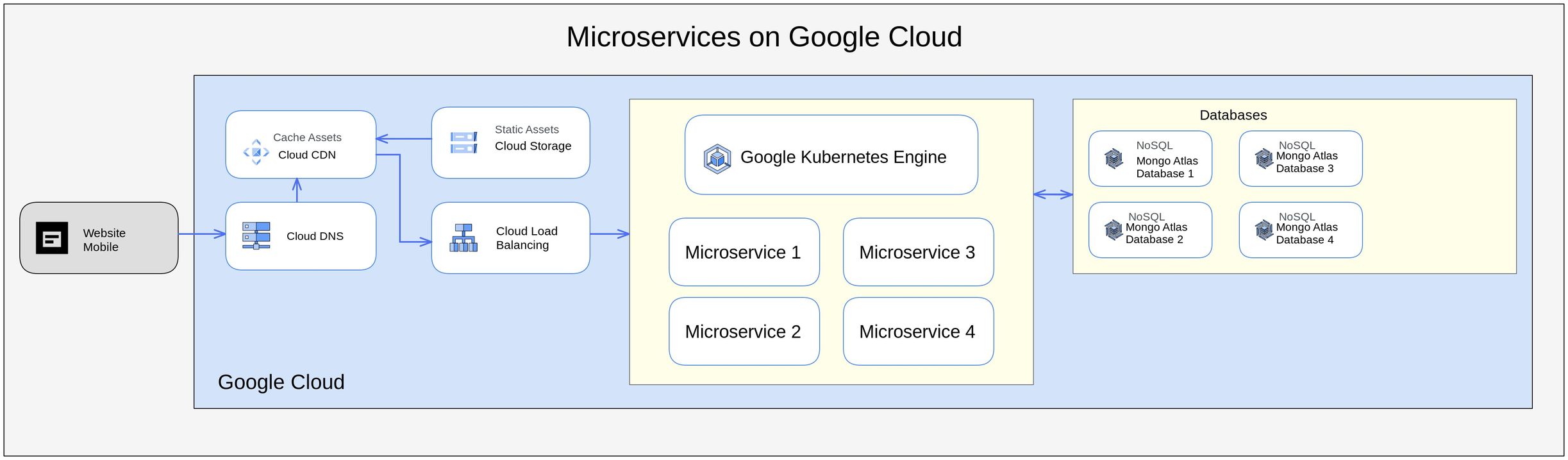
Phase 2: Migration Process
Migrating from a self-hosted MongoDB cluster to MongoDB Atlas using the mongomirror tool can be a complex process, and there are several potential issues that can arise. Here are some common problems that we encountered during the migration process:
- Connectivity issues: The mongomirror tool relies on a stable network connection between the source and destination clusters. If there are network issues or connectivity problems, it can result in data loss or corruption. It is important to ensure that the network connection is stable and to monitor the progress of the migration closely.
To solve this problem we were relying on the underlying cloud infrastructure, which provided us with the necessary reliability to complete the transfer with no connectivity issues. - Resource utilization: The mongomirror tool can be resource-intensive, particularly during the initial sync process. However with careful planning and testing we were able to find the necessary balance needed for the amount of resources to allocate for our mongomirror jobs.
- Security concerns: Migrating data from a self-hosted MongoDB cluster to MongoDB Atlas involves transferring sensitive data over the internet. It is important to ensure that the data is encrypted during transit and that the destination cluster has adequate security measures in place to protect the data. Fortunately we had our private VPC peering connection, so the risk factor here was non-existent.
- Index creation and build on target clusters: This was one of the issues that we have faced during our mongo migration pipeline. The fact that bigger collections with large indices required almost the same amount of time and sometimes longer than the actual db copy. When the mongomirror performs the sync, it is done in a hybrid manner whereas an individual index build submitted follows the specific MongoDB version.
MongoDB 4.2 index builds obtain an exclusive lock on only the collection being indexed during the start and end of the build process to protect metadata changes. The rest of the build process uses the yielding behavior of background index builds to maximize read-write access to the collection during the build. 4.2 index builds still produce efficient index data structures despite the more permissive locking behavior.
With some careful planning and maintenance window we were actually able to mitigate that risk and index creation didn’t cause issues during the migration process.
Phase 3: Testing and Validation
After initial migration to each service we were able to test how connection works, thanks to our approach and automated tooling that we built were able to select, transfer and in case of an issue rollback to previous cluster every single database.
Post-migration
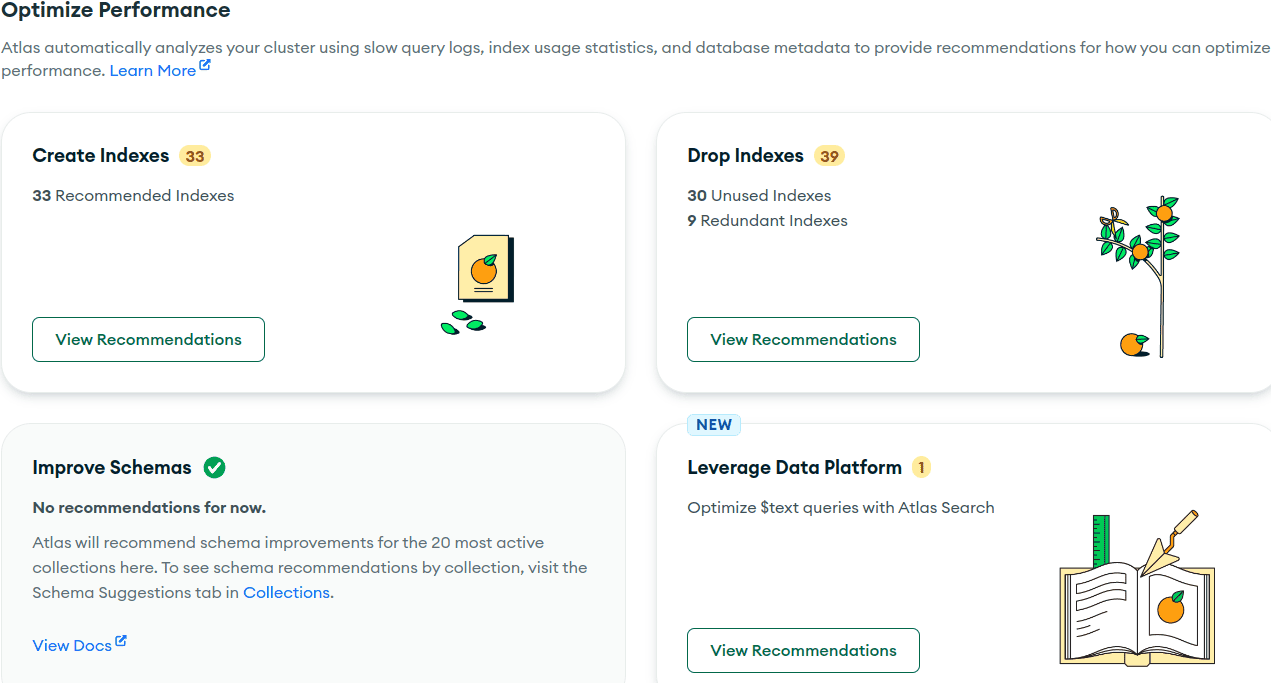
After migration we were able to fully benefit for all features that Mongo Atlas provides for better overview of our service usage:
Performance Advisor:
Profiler:
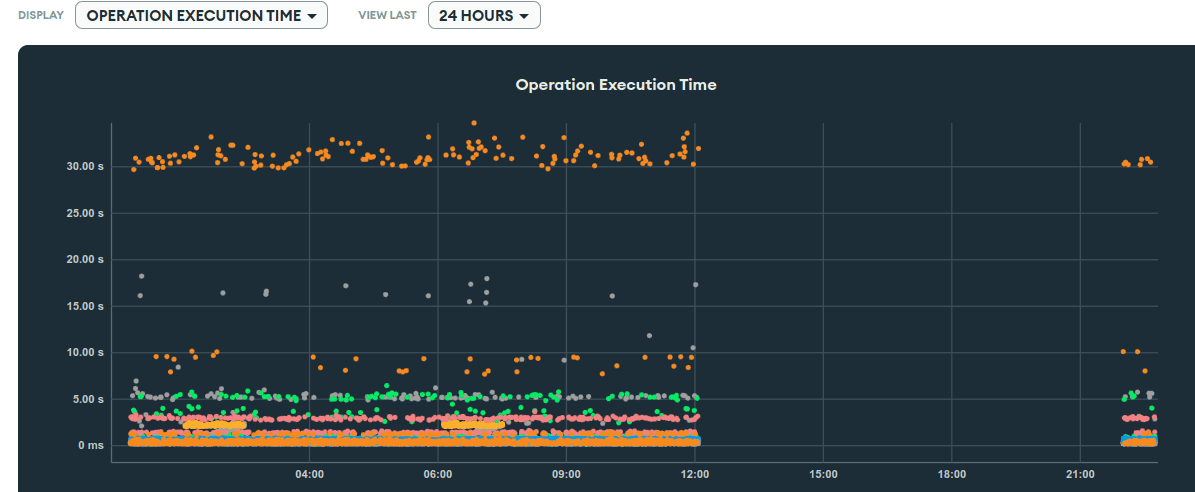
Real time performance monitor:
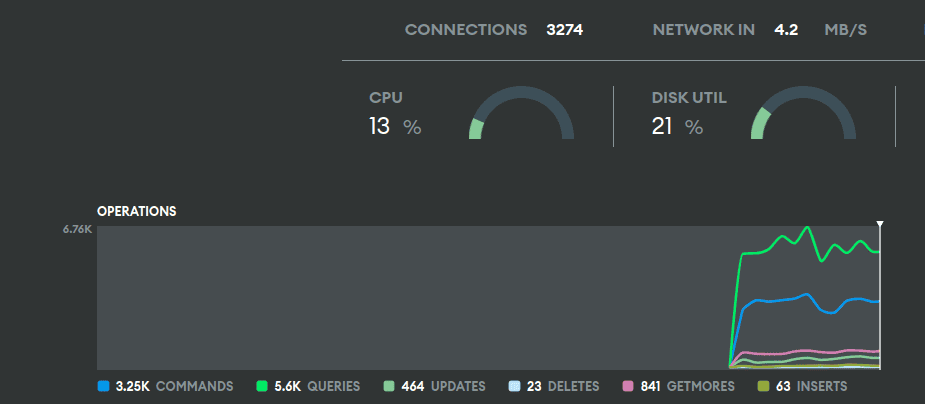
After transfer we were able to see graphs like this one showing the boost of performance power:


Conclusions
The migration process required careful planning, preparation, and execution to ensure a successful transition to the new infrastructure. By following this plan and leveraging the available resources and support, we minimized the downtime and disruption to our operations and ensured the availability and performance of our applications during the migration process and now we are happy Atlas users.
Author: Infrastructure Team
We've got our finger on the pulse